Perspectives
Enterprise Playbook for Multi-Agent Systems
Google Just Published the Enterprise Playbook for Multi-Agent Systems. Here's What Most Teams Are Getting Wrong.

Build, Scale, Govern — The 3-Phase Framework That Separates Agent Demos from Agent Products
39% of executives say they've launched more than 10 AI agents. Yet nearly two-thirds of organizations can't get them past the prototype stage. Google Cloud's new enterprise guide explains why — and the answer has almost nothing to do with the model.
Source: find full report here.
The Guide Everyone Should Read (But Few Will Finish)
Google Cloud released an enterprise technical guide to multi-agent systems. It's dense, thorough, and openly opinionated about what it takes to move AI agents from prototype to production.
I read it closely — not as a developer, but as a product manager asking the same question every PM building with AI agents is asking right now: why do so many agent projects stall between "impressive demo" and "running in production"?
The guide answers that question directly. And the answer is uncomfortable for teams that have been pouring resources into the build phase while treating everything else as an afterthought.
The 90/10 Problem
Here's the pattern I see across every organization experimenting with AI agents: 90% of the effort goes into building the agent. 10% goes into everything that actually determines whether the system survives in production.
The numbers confirm this isn't just anecdotal. According to McKinsey's State of AI research, fewer than one in four enterprises have successfully scaled agents to production, even though nearly two-thirds are experimenting with them. KPMG's Q4 2025 AI Pulse Survey found that 65% of leaders cite agentic system complexity as the top deployment barrier — not model quality, not capability, but the operational complexity of running agents at scale. And Gartner predicts that 40% of enterprise applications will integrate task-specific AI agents by end of 2026, up from less than 5% in 2025. The demand is there. The production capability isn't.
Google's guide frames this as a lifecycle problem, not a technology problem. They propose three phases: Build, Scale, Govern. Most teams only invest seriously in phase one. The ones shipping agents in production are spending equal time on all three.
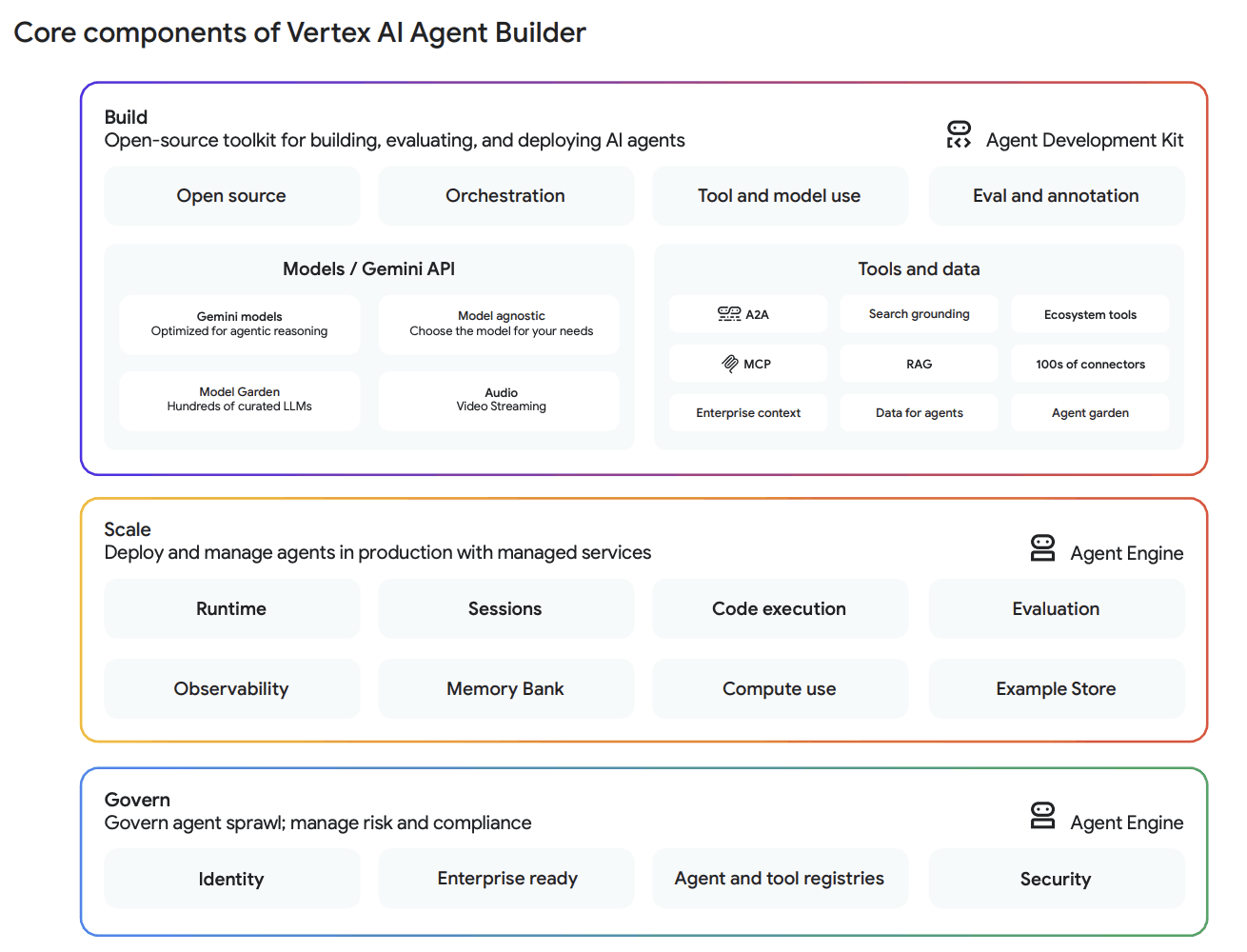
Let me walk through each phase — not as a summary of Google's marketing, but as a PM's analysis of what actually matters for product teams building with agents.
Phase 1: Build — The Part Everyone Understands (Mostly)
The build phase is the most intuitive. You pick a framework, choose a model, define tools, connect data sources, and get an agent doing something useful. Google's platform for this is Vertex AI Agent Builder, with the open-source Agent Development Kit (ADK) at its center.
What's worth noting about Google's approach is the emphasis on openness and choice. ADK supports Python, Java, Go, and TypeScript, and is designed to get developers started in under 100 lines of code. But it also lets you bring other frameworks — LangGraph, CrewAI, AG2, LlamaIndex — so teams can build within their preferred ecosystem while still deploying to Google Cloud's managed platform. The model choice is similarly open: Gemini models optimized for agentic reasoning, or any other model through Model Garden.
This matters for product teams because framework lock-in is one of the biggest risks in the current agent landscape. The ecosystem is evolving so fast that teams adopting a single framework risk rebuilding their entire stack within months. The Cleanlab AI Agents in Production survey found that a significant portion of regulated enterprises rebuild their AI agent stack every three months or faster. Building on an open, framework-agnostic foundation isn't a nice-to-have — it's a survival requirement.
The Architecture Decision That Shapes Everything
The guide makes an important distinction in agent architecture that most teams gloss over: the choice between LLM-based agents (non-deterministic, flexible) and workflow agents (deterministic, predictable). ADK organizes these into clear categories — LLMAgent for complex reasoning, SequentialAgent for fixed-order pipelines, ParallelAgent for simultaneous independent tasks, LoopAgent for iterative refinement, and CustomAgent for unique requirements.
This isn't a technical implementation detail. It's a product decision. As a PM, the question isn't "which agent type is most powerful?" but "what level of predictability does my use case require?" A customer support agent that handles open-ended conversations needs LLM flexibility. An invoice processing pipeline needs deterministic sequence. Most production systems need a combination — and the architectural choice you make here ripples through every subsequent phase.
The ReAct Loop: How Agents Actually Work
For readers who haven't built with agents directly, the guide provides a clear explanation of the foundational ReAct paradigm — Reasoning, Action, Observation. The agent reasons about the user's prompt, decides on an action (calling a tool or delegating to a sub-agent), observes the result, and feeds it back into the next reasoning step.
What struck me is how much emphasis the guide puts on tool definitions as contracts. For a model to use a tool correctly, the guide specifies that each tool needs a descriptive function signature with explicit type hints, a docstring that precisely defines purpose and usage criteria, a structured return schema with status keys for success/error, and stateful context access. This is meticulous, and intentionally so. In production systems, a poorly defined tool isn't just a bug — it's an agent that silently does the wrong thing. The guide's insistence on unambiguous API contracts reflects the reality that agents are only as reliable as the tools they're given.
The Protocols: MCP, A2A, and AP2
The build phase also introduces three protocols that are reshaping how enterprise agents connect and communicate. Understanding these protocols is crucial for any PM thinking about agent interoperability.
MCP: The Universal Adapter for Data
Model Context Protocol (MCP) is an emerging open standard for connecting AI agents to external data sources and tools. Instead of building custom point-to-point integrations for each database or service, MCP provides one standard layer. An ADK agent can act as an MCP client, consuming tools exposed by any MCP server. Developers can also wrap their own ADK tools in an MCP server, making them available to any MCP-compliant agent.
The practical impact: your agent can connect to BigQuery, AlloyDB, Cloud SQL, Spanner, Postgres, MySQL, and others through a single integration layer. Google provides both an open-source MCP Toolbox for Databases and fully managed remote MCP servers for production environments.
For product teams, MCP means the integration cost of connecting agents to enterprise data drops dramatically. Instead of weeks of custom integration for each data source, you get a standard connector. This changes the ROI math on agent projects — data access was often the most expensive and slowest part of building enterprise agents.
A2A: Solving the Hardest Problem in Multi-Agent Systems
If MCP handles agent-to-tool communication, the Agent2Agent (A2A) protocol handles the harder problem: getting agents built by different teams, on different frameworks, to actually talk to each other.
A2A was launched in April 2025 with support from over 50 technology partners, including Atlassian, Box, Intuit, MongoDB, PayPal, Salesforce, SAP, ServiceNow, UKG, and Workday. By July 2025, the protocol reached version 0.3 with over 150 organizations supporting it. In June 2025, Google donated A2A to the Linux Foundation, with AWS, Cisco, Microsoft, Salesforce, SAP, and ServiceNow joining as founding members.
The protocol works through a surprisingly elegant mechanism. Each agent publishes an "agent card" — a JSON file at a well-known endpoint that advertises its capabilities, endpoint URL, and authentication requirements. Other agents discover it, see what it can do, and send tasks to it. Interactions are framed as tasks with defined lifecycle states: a client agent sends a task request to a server agent, which processes it and returns a response.
The Box case study in the guide illustrates the real-world application. Box built an A2A-enabled agent with Google's ADK and Gemini that connects to their Intelligent Content Management platform. Users ask complex questions in natural language and receive summarized, contextual answers from documents instantly. The agent integrates with Gemini Enterprise and is available on Google Cloud Marketplace.
Geotab, a telematics company, uses ADK as the framework for their AI Agent Center of Excellence. Their VP of Data & Analytics described it as providing the flexibility to orchestrate various frameworks under a single, governable path to production.
AP2: Agents That Can Pay
This is the one that's early but fascinating from a product perspective. The Agent Payments Protocol (AP2) is an open protocol for handling autonomous agent transactions. It addresses three problems that current systems can't solve: authorization (proving a user gave an agent specific purchasing authority), authenticity (ensuring an agent's request reflects the user's true intent), and accountability (determining responsibility for incorrect transactions).
AP2 supports multiple payment methods — credit cards, debit cards, stablecoins, real-time bank transfers — and works as an extension of A2A and MCP. The implications for product managers building commerce-adjacent agents are significant: if your agent can transact autonomously, you need a completely different trust layer than if it just answers questions.
Phase 2: Scale — Where Most Agent Projects Die
The build phase gets the attention. The scale phase gets skipped. And then teams wonder why their agent works in a demo but fails at 1,000 concurrent users.
Google packages the scale capabilities in Vertex AI Agent Engine — managed services including runtime, sessions, memory, and sandboxes. The key capabilities map directly to the problems that kill agent projects in production.
The Runtime Problem
ADK is deployment-agnostic by design: your agent logic is decoupled from the serving infrastructure. You develop and test locally, then deploy the same code to production. Agent Engine provides automated scalability, integrated security and authentication, framework-agnostic support, and lifecycle management APIs for creating, reading, updating, and deleting deployed agents.
This sounds like basic infrastructure. It is. And the absence of it is why agents fail. An agent that can't scale to meet varying user loads, that doesn't have integrated identity management, that requires custom deployment pipelines for each framework — that's an agent that dies in production review.
The Evaluation Loop: What Separates Demos from Products
The guide's approach to evaluation is one of the most pragmatically useful sections. Two key capabilities stand out.
First, Example Store: a centralized repository to store and dynamically serve few-shot examples. This lets you steer agent performance and improve accuracy on specific tasks without retraining the model. The ability to improve behavior through examples rather than fine-tuning is huge for teams running multiple agents — you can adjust behavior quickly, at low cost, without touching the underlying model.
Second, the Evaluation Service: a feedback loop system for reviewing agent responses and trajectories at scale. You benchmark performance against specific quality metrics and proactively identify failure modes before they reach production.
The guide explicitly positions this as moving beyond "vibe-testing" — a pointed phrase that captures what most teams are actually doing. If your agent evaluation process consists of a few people trying prompts and saying "yeah, that seems right," you don't have a production agent. You have a demo.
Sandboxes for Autonomous Execution
For agents that execute code or interact with computer interfaces, the guide makes a blunt statement: a sandbox environment isn't just a best practice — it's essential. Code Execution lets agents run code in isolated, managed environments created in under a second. Computer Use lets agents control a computer's graphical interface by mimicking human interactions.
Both capabilities require isolation. An agent that can execute arbitrary code in a production environment is a security incident waiting to happen. The sandbox is the difference between an agent that's useful and an agent that's dangerous.
Phase 3: Govern — The Phase That Determines Everything
Google's guide saves governance for last, and I think that sequencing is deliberate. Most teams reach governance as an afterthought — "we'll figure out security and compliance later." The guide's argument is that governance is what makes everything else possible.
The numbers support this. KPMG's Q4 survey found that 75% of leaders cite security, compliance, and auditability as the most critical requirements for agent deployment. Deloitte's 2026 AI report found that only one in five companies has a mature model for agentic AI governance. The gap between "we have agents running" and "we have agents running with proper oversight" is enormous.
Agent Identity
This is the governance capability I found most important. Agent Identity gives every agent its own unique, native Google Cloud identity with granular permissions and a full audit trail. Not a login. Not a shared service account. A real, managed identity.
Without agent identity, you have no accountability. When an agent makes a decision at 2am that affects a customer account, you need to know which agent did it, what permissions it had, what data it accessed, and what actions it took. Shared credentials or generic service accounts make forensic investigation nearly impossible. Individual agent identity makes it tractable.
The Observability Suite
The suite provides monitoring dashboards, detailed tracing, and an interactive playground for debugging. The use cases are practical: finding policy violations proactively, conducting forensic investigations after incidents, and simplifying compliance auditing.
For regulated industries — financial services, healthcare, insurance — this isn't optional. It's the difference between deploying agents and being allowed to deploy agents by your compliance team.
Agent and Tool Registry
A centralized system to manage, version, and discover approved agents and tools. It promotes reusability, consistency, and control across the organization, ensuring developers use vetted and compliant components.
This is governance at the organizational level. As agent counts scale (remember, 39% of executives have already launched more than 10), the risk of "agent sprawl" — unvetted agents using unapproved tools to access sensitive data — becomes the primary operational risk. A registry is how you prevent it.
Model Armor and Security Command Center
The security layer screens LLM prompts and responses for prompt injection, jailbreak attempts, data exfiltration, and sensitive data leakage. Security Command Center provides continuous vulnerability scanning, real-time threat detection, and security posture monitoring across the entire agent fleet.
The practical use cases the guide lists are telling: preventing chatbots from recommending competitor solutions, filtering AI-generated social media content for harmful messaging, mitigating PII leakage in prompts. These aren't theoretical risks — they're incidents that have already happened in production agent deployments.
What the Guide Really Says (When You Read Between the Lines)
Strip away the Google Cloud marketing and the guide's core argument is this: the technology for building agents is mature. The challenge is the operational infrastructure — identity, observability, security, evaluation, governance — that makes agents production-ready.
This maps precisely to what the industry data shows. The Gartner prediction (40% of enterprise apps with agents by end of 2026, up from 5% in 2025) tells you where the market is going. The KPMG finding (65% of leaders citing system complexity as the top barrier) tells you what's in the way. The McKinsey data (fewer than 1 in 4 enterprises scaling agents to production) tells you how hard the path actually is.
The teams that are succeeding — Box, Geotab, the financial services and airline examples in the Deloitte report — aren't succeeding because they have better models. They're succeeding because they've invested equally in all three phases: build, scale, and govern.
What This Means for PMs Building Agent Products
If you're a product manager working on or evaluating AI agents, the guide crystallizes several decisions you need to make now.
Choose framework-agnostic architecture from day one. The agent ecosystem is evolving too fast to lock in. Build on platforms that support multiple frameworks and models. Your agent stack will change — the question is whether you can swap components without rebuilding everything.
Budget equal time for scale and governance as for build. If your sprint planning allocates two months for building the agent and two weeks for "deployment and security," invert that ratio. The deployment infrastructure and governance controls take as long as the core agent logic — and they're what determines whether your agent survives contact with production.
Define your agent identity model before you write any agent code. Who is the agent acting as? What permissions does it have? What audit trail does it leave? These questions need answers in the product spec, not in the incident retrospective.
Build your evaluation loop on day one. Not after launch. Not in v2. From the first sprint, define how you measure agent quality, how you identify failure modes, and how you improve behavior without retraining. The Example Store pattern — steering through few-shot examples — is a product-level capability that should be designed, not bolted on.
Watch the protocol convergence. MCP for agent-to-tool, A2A for agent-to-agent, AP2 for agent-to-payment. These three protocols are becoming the connective tissue of multi-agent systems. Product decisions made in ignorance of these standards will create technical debt within months.
The Truth
The guide's conclusion puts it plainly: "The challenge is no longer if agents deliver value, but how to deploy them with enterprise confidence."
That confidence comes from three things: identity (knowing what your agents are doing), observability (proving what your agents did), and security (preventing your agents from being exploited). None of these are exciting. None of them make good demos. And all of them are what separate the teams shipping agents from the teams still presenting prototypes.
Most teams only invest in phase one. The ones shipping agents in production are spending equal time on all three.
If you're building AI agents right now, go read the full guide. The link is below. And then ask yourself honestly: which phase is getting 90% of your time?
Because the answer to that question is also the answer to why your agents aren't in production yet.
View more articles
Learn actionable strategies, proven workflows, and tips from experts to help your product thrive.


