Automation
Generative AI for Enterprise Product Information Management
Sample report: AI for Enterprise Product Information Management

Generative AI for Enterprise Product Information Management
Important this is sample report for demo purpose.
Executive summary
Large enterprises are under simultaneous pressure to (a) publish richer, more accurate product information across more channels and geographies, faster; (b) meet emerging sustainability and product-passport-style transparency requirements; and (c) make generative AI (GenAI) investments productive rather than experimental. Product Information Management (PIM)—as the enterprise “system of record” for product attributes, hierarchies, assets, and downstream syndication—has become a high-leverage control point for GenAI because GenAI is only as reliable as the structured product data it can be grounded in.
This report’s core finding is that GenAI creates the most durable enterprise value in PIM when it is implemented as governed automation (human-in-the-loop, traceable sources, policy-aware workflows), not as a “chatbot on top of the catalog.” Industry and vendor evidence shows:
consumers abandon purchases when product information is incomplete or inconsistent,
retailers and brands see significant benefits from accelerating product listing and improving data quality and governance, and
enterprise AI success is constrained by data availability and quality.
Recommendation for an Enterprise Investment Committee (EIC):
Adopt a “Buy the PIM foundation, Build the GenAI layer” strategy unless the enterprise already has a mature PIM/MDM hub that is extensible and meets scalability and governance requirements. The investment case is strongest when GenAI targets measurable bottlenecks: supplier onboarding and attribute extraction, catalog enrichment, localization, regulatory/sustainability documentation readiness (e.g., Digital Product Passport-related data), and continuous data quality improvements.
Why now (2026 context):
GenAI adoption in enterprises accelerated sharply in 2023–2024, moving from pilots toward regular use, raising expectations for production-grade governance and ROI.
The EU AI Act has a staged application timeline (prohibited practices effective Feb 2025; GPAI obligations applicable Aug 2025; transparency rules begin Aug 2026; certain high-risk rules extend to Aug 2027), increasing board-level scrutiny for AI risk management and documentation.
The EU is operationalizing the Ecodesign for Sustainable Products Regulation (ESPR) and Digital Product Passport (DPP) program, and DPP-style requirements—starting with batteries—create product-data transparency demands that PIM functions are best positioned to coordinate.
Trends overview
Enterprise PIM is a growing market, with forecasts generally indicating double-digit CAGR through the late 2020s, though absolute market-size figures vary by analyst methodology and scope (PIM-only vs. adjacent PXM/MDM/syndication). For example, one 2021–2027 forecast estimates growth from $10.5B (2021) to $20.2B (2027) at ~11.5% CAGR, while other firms publish higher or lower endpoints depending on segmentation.
Interpretation for EIC: the market signal is less about the exact dollar figure and more about (a) sustained enterprise spend on product data foundations and (b) a shift from “PIM as catalog admin” to “PIM as product experience + compliance data hub,” which is consistent with independent vendor evaluations and solution positioning.
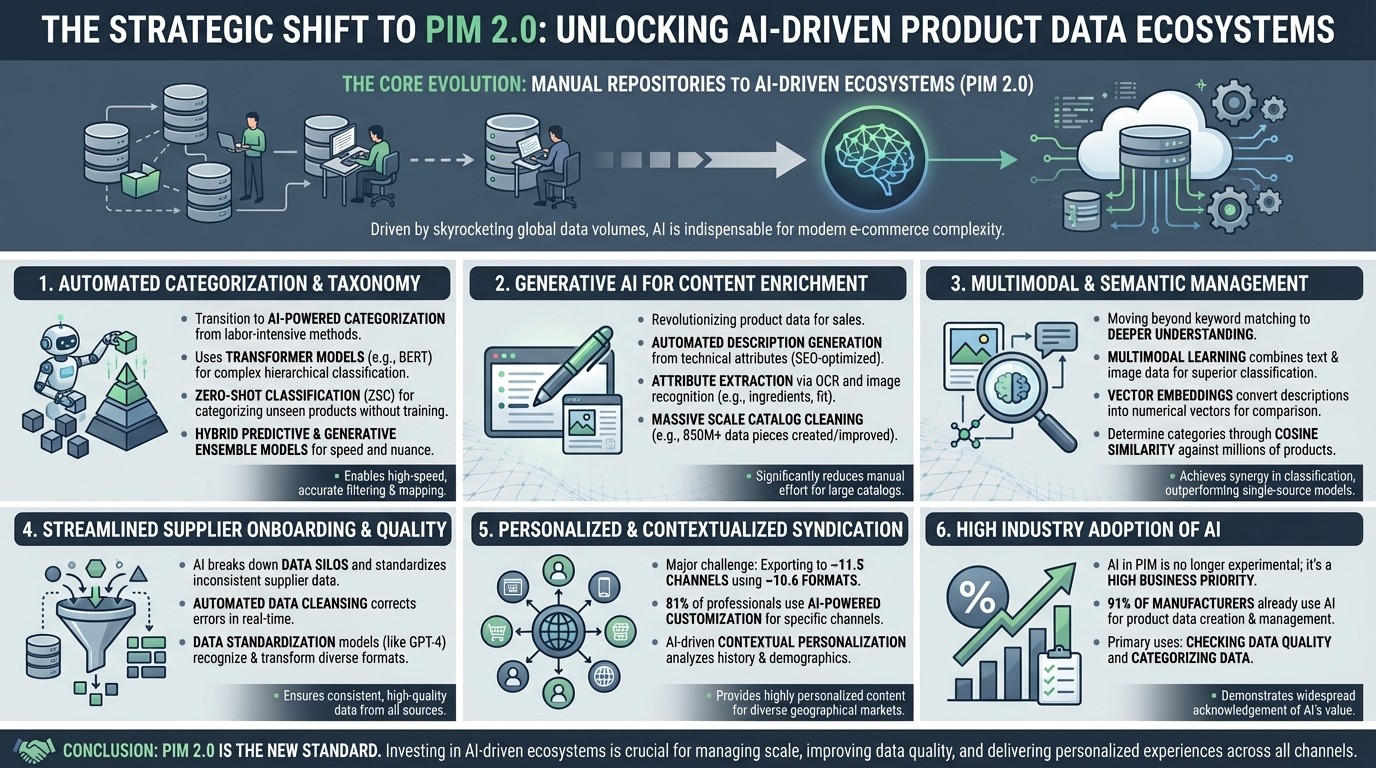
The core trends in Product Information Management (PIM) are currently defined by a profound shift from manual, static data repositories toward AI-driven, automated ecosystems, often referred to as "PIM 2.0". As global data volumes skyrocket, AI has become indispensable for managing the complexity of modern e-commerce catalogs.
The following are the core trends:
1. Automation of Product Categorization and Taxonomy
The most significant trend is the transition from labor-intensive manual classification to automated AI-powered categorization.
Transformer Models: Technologies like BERT and DistilBERT are being fine-tuned to accurately classify products into complex hierarchical taxonomies based on titles and descriptions.
Zero-Shot Classification (ZSC): This groundbreaking technique allows organizations to categorize products into new or unseen classes using pre-trained Large Language Models (LLMs) without a traditional training phase.
Predictive and Generative Ensemble Models: Leading retailers like Walmart use a hybrid approach ("Ghotok"), combining predictive AI (for high-speed filtering) with generative AI (for nuanced semantic understanding) to map relationships between categories and product types.
2. Generative AI for Content Enrichment
Generative AI is revolutionizing how product data is "enriched" to drive sales.
Automated Description Generation: LLMs are used to generate compelling, accurate, and SEO-optimized product descriptions from raw technical attributes.
Attribute Extraction: AI can now automatically extract key features (e.g., ingredients via OCR, or color and fit via image recognition) from supplier spreadsheets, documents, and images.
Massive Scale Catalog Cleaning: Walmart, for example, used multiple LLMs to create or improve over 850 million pieces of data in its catalog, a task that would have previously required 100 times the headcount.
3. Multimodal and Semantic Data Management
PIM systems are moving beyond simple keyword matching toward deeper semantic and visual understanding.
Multimodal Learning: New models combine textual data with image data to achieve synergy in classification, outperforming single-source classifiers.
Vector Embeddings: Descriptions are being converted into numerical vectors to determine categories through cosine similarity, comparing new items against millions of already categorized products.
4. Streamlined Supplier Onboarding and Data Quality
AI is being used to break down data silos and standardize inconsistent data arriving from various suppliers.
Automated Data Cleansing: AI algorithms identify and correct misspellings, illogical values, and formatting discrepancies in real-time.
Data Standardization: Models like GPT-4 are programmed to recognize different terminologies and formats used by various suppliers and transform them into a standardized internal format.
5. Personalized and Contextualized Syndication
Exporting product data to diverse channels has become a major challenge, with organizations now publishing to an average of 11.5 different places using 10.6 different formats.
AI-Powered Customization: 81% of industry professionals now use AI to customize product data (text, images, etc.) for specific sales channels.
Contextual Personalization: AI-driven PIM systems analyze browsing history and demographics to provide highly personalized product recommendations and localized content for different geographical markets.
6. High Industry Adoption of AI
The use of AI in PIM is no longer experimental; it is a high business priority. An industry report found that 91% of manufacturers already use AI to support product data creation and management, primarily for checking data quality and categorizing data.
Commercial and operating model trends
PIM broadening into PXM ecosystems: Independent evaluation describes vendors bridging PIM with DAM, syndication, and analytics, reflecting a market shift toward end-to-end product content lifecycle management rather than a single repository.
Cloud-first delivery and composability: Vendor positioning emphasizes API-first integration and hybrid deployment options (cloud/on‑prem/hybrid), which matters for data residency, latency, and integration with ERP/PLM landscapes.
Regulatory and policy drivers affecting GenAI-for-PIM
EU AI Act staged obligations: The EU framework defines risk levels; sets requirements such as logging/traceability, documentation, human oversight, robustness/cybersecurity for high-risk systems; and introduces GPAI-provider obligations and transparency requirements with staged applicability from 2025–2027.
EU Data Governance Act: Entered into force in June 2022 and applicable since September 2023, aiming to increase trust in data sharing and support “Common European Data Spaces,” with explicit linkage to AI training and data availability.
Digital Product Passport momentum (ESPR + sectoral rules): The EU’s ESPR implementation explicitly includes DPP technical preparation (identifiers, data carriers, access rights, registry/portal) and includes a working-plan mechanism; parallel work on battery passports highlights 2027 as the legal requirement start for batteries, illustrating near-term pressure on product attribute traceability.
Use cases and value
PIM programs typically fail to scale because product information is fragmented across ERP/PLM/supplier inputs, with manual collection and validation (spreadsheets + email) causing delays and errors; TEI evidence shows that replacing manual supplier communications and data collection can materially accelerate listing and reduce errors.
Consumer research underscores the commercial risk of incomplete or inconsistent product content: more than 83% of global consumers reported willingness to switch sites when they can’t find sufficient product information, and 73% report a negative brand perception when product information is incomplete or inaccurate online.
High-value GenAI use cases in enterprise PIM
Supplier onboarding and attribute extraction (highest ROI starting point)
GenAI (often combined with OCR/vision models and rules) extracts structured attributes from supplier catalogs, PDFs, manuals, certifications, safety data sheets, and images; it proposes mappings to internal attribute schemas, flags missing values, and generates “questions back to supplier.” This aligns with common PIM ingestion models that explicitly include ERP/PLM/supplier feeds and AI-driven mapping/structuring.
Catalog enrichment and normalization
Generate draft product titles, long/short descriptions, bullets, and channel-specific variants from structured attributes, then route for approval.
Deduplicate and harmonize attribute values, detect anomalies, and recommend standard formats, using ML/GenAI-assisted “data cleansing” loops.
Localization at scale
Translate product content and adapt it to regional compliance and merchandising conventions, with built-in approval workflows and governance.
Digital shelf optimization and continuous improvement
Summarize customer feedback and reviews into attribute improvements and content updates, closing the loop between performance signals and PIM enrichment.
Prioritize enrichment impact by correlating completeness with conversion/returns signals; consumer evidence links product content quality to abandonment and dissatisfaction/returns.
Compliance and sustainability data readiness (DPP-era preparation)
Extract and maintain structured evidence for product composition, materials, origin, and other regulated disclosures; support traceability and data sharing needed for DPP initiatives (battery passports first, broader product groups next).
Value drivers, KPIs, and “what good looks like”
A rigorous EIC investment case should tie GenAI-for-PIM to value drivers that are measurable and auditable. The table below lists recommended KPIs and why they matter.
Value driver | KPI (definition) | Measurement approach | Why it matters |
|---|---|---|---|
Faster time-to-market for new products and changes | Listing cycle time (supplier-ready → live on channel), change lead time (request → published) | Timestamp events from workflows, channel publish logs | TEI studies show material gains from accelerated listing (e.g., 28-day reduction in a composite case). |
Lower operating cost in content operations | Hours per SKU for onboarding/enrichment/localization; % automation coverage (drafts created by AI + approved) | Time tracking by step; workflow instrumentation | Manual processes are explicitly cited as costly; GenAI reduces drafting burden and shifts effort to review. |
Better product content quality | Completeness (% required fields populated), consistency (cross-channel value match), error rate (post-publish corrections) | Data-quality rules + sampling; retailer rejection logs | Consumers abandon purchases when information is insufficient or inconsistent. |
Reduced compliance exposure | Non-compliance incidents (labeling errors, regulated-claims issues), audit readiness (% evidence linked) | Incident log + traceability links | TEI evidence includes quantified value for avoiding non-compliance penalties. |
Example ROI calculations and explicit assumptions
Below are illustrative ROI scenarios for a large enterprise (multi-brand, multi-country). These are not vendor quotes; they are modeling examples to show how an EIC can evaluate sensitivity. TEI evidence is provided separately to anchor plausibility of listing-cycle improvements and the existence of large-value outcomes.
Assumptions (Base Case)
250,000 active SKUs; 60,000 new SKUs/year; 5 languages.
Current effort per new SKU: 45 minutes (attribute mapping + description drafting + QA) per language equivalent, blended through shared work.
Fully loaded labor cost: $75/hour (content ops + data stewards + QA blended).
GenAI reduces drafting/structuring effort by 35% in Year 1, 50% in Year 2+, due to prompt libraries, improved retrieval grounding, and workflow tuning.
Implementation cost: $3.5M one-time (integration + change management + governance), plus $1.2M/year run cost (licenses, LLM usage, observability, support).
Discount rate: 10% (within TEI’s typical range of 8–16%).
ROI scenarios (illustrative)
Scenario | Labor savings (annual) | Revenue uplift (annual) | Total annual benefit | 5-year NPV (10% discount) | Break-even |
|---|---|---|---|---|---|
Conservative | $2.0M | $0.5M | $2.5M | ~$4.3M | Year 3 |
Base | $3.2M | $1.5M | $4.7M | ~$11.0M | Year 2 |
Aggressive | $4.5M | $3.0M | $7.5M | ~$19.5M | < Year 2 |
Notes on “revenue uplift” modeling: In practice, uplift should be tied to specific measurable levers (e.g., fewer abandoned sessions, fewer returns driven by expectation mismatch) rather than a generic conversion increase; consumer research provides strong directional evidence that insufficient product info drives abandonment and dissatisfaction/returns.
Technical architecture
A production-grade GenAI-for-PIM capability is best implemented as an augmentation layer around the enterprise’s product-data foundation (PIM/MDM), with RAG grounding, workflow controls, and security-by-design. This aligns with both (a) independent observations that PIM’s role is broadening across creation/enrichment/distribution and (b) cloud reference architectures for RAG systems.
image_group{"layout":"carousel","aspect_ratio":"16:9","query":["enterprise product information management architecture diagram","product information management workflow governance","knowledge graph product catalog architecture","retrieval augmented generation enterprise architecture"],"num_per_query":1}
Reference architecture (recommended)
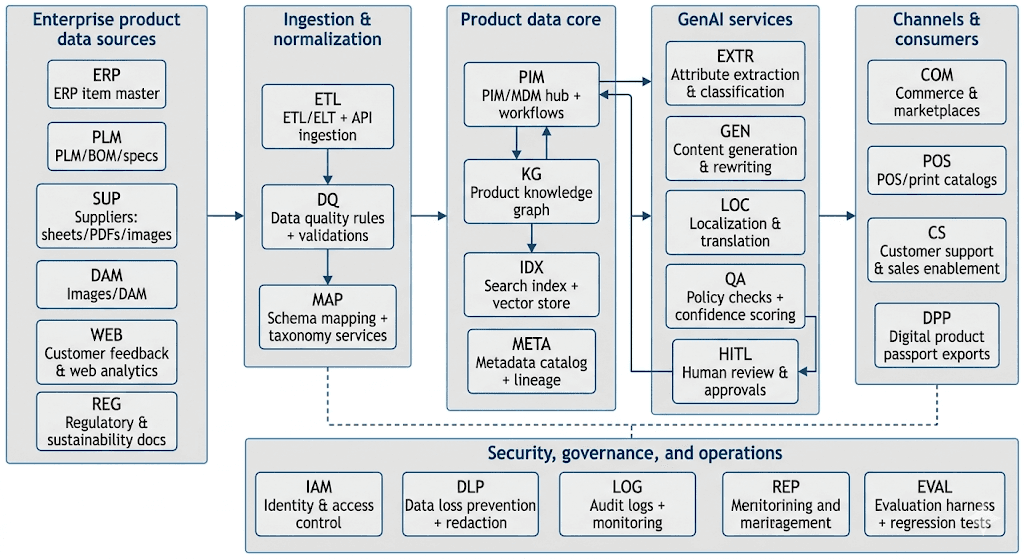
This architecture emphasizes:
Grounding and traceability: RAG and knowledge graph grounding reduce factual errors by pulling from curated sources, consistent with RAG surveys describing hallucination reduction via external references.
Workflow as the control plane: GenAI outputs should enter the same approval and governance workflows as human-authored changes; vendors explicitly emphasize “human-in-the-loop” and approvals for product content creation.
Scalability: Indexing + retrieval + generation pipelines match canonical RAG steps (indexing chunks/vectors, retrieval top‑k, generation with retrieved context).
Data sources, ingestion, metadata, and knowledge graphs
Product data commonly originates in ERP/PLM plus supplier-provided materials; enterprise PIM solutions explicitly support aggregating data from many systems and onboarding supplier/manufacturer data.
For DPP and sustainability readiness, the data model must support:
multi-tier composition attributes (materials, substances, origins),
evidence attachments (certificates, test results),
and controlled visibility/access rights for different stakeholders.
Battery-passport research highlights DPP as a tool to register/process/share product-related information and notes batteries as the first group with a legal requirement as of 2027; the EU ESPR implementation confirms ongoing DPP infrastructure preparation (identifiers, data carriers, access rights, registry/portal).
LLM layer: RAG, integration patterns, and deployment options
RAG pattern (default): Cloud provider documentation describes RAG architectures for answering questions from custom documents and enterprise content, and enterprise surveys of RAG outline paradigms and evaluation approaches.
Integration patterns for PIM workflows
Synchronous API calls (e.g., “generate draft description” within the PIM UI) for interactive productivity, as reflected in vendor “accelerator” patterns.
Asynchronous job orchestration (bulk generation, re-classification, translation jobs) with durable queues/state machines to manage throughput and retries; this is a practical response to “model denial-of-service” and cost controls identified in GenAI security guidance.
Event-driven enrichment (publish/approve triggers downstream exports) to ensure deterministic propagation and auditability, matching PIM’s governance emphasis.
Deployment choices
Cloud (fastest innovation, managed RAG services) vs. on-prem/hybrid (data residency, latency, regulatory constraints). PIM vendors explicitly position hybrid and composable deployment options; cloud provider guidance also emphasizes secure enterprise RAG patterns and search grounding.
Competition landscape
Independent evaluation identifies a cohort of significant PIM providers (10 vendors in one widely cited evaluation) and characterizes strengths such as marketer-focused enrichment vs. governance-centric MDM approaches.
To make this actionable for an EIC, competition should be assessed along two axes:
PIM/MDM foundation maturity (data model, governance, workflow, syndication, integrations), and
GenAI productization (embedded GenAI features, prompt libraries, workflow integration, safety controls, observability).
Vendor comparison (publicly documented capabilities)
The table below combines (a) independent evaluation positioning and (b) vendor-published capabilities. Sources include the Forrester Wave evaluation and vendor product/press materials.
Vendor | Foundation strength (PIM/MDM) | GenAI/PIM capability signal | Typical fit | Noted strengths |
|---|---|---|---|---|
IBM | Governance-centric MDM + PIM; API-first/hybrid positioning | “AI-powered PIM” positioning; enrichment/validation automation messaging | Large enterprises needing strong governance and complex aggregation | Strong governance/process support in independent evaluation context |
Informatica | MDM-centric PIM; strong ingestion/governance; higher tech orientation | GenAI direction via CLAIRE GPT + “agentic AI” positioning for product experiences | Enterprises already standardized on MDM stack | Strength in core PIM + governance; roadmap focus on automation/AI |
SAP | MDG governance across domains in hybrid landscapes | Roadmap includes generative AI-assisted changes and Joule copilot dialog support in governance | Enterprises with strong SAP footprint | Deep integration with SAP processes; governance-oriented roadmap |
Stibo Systems | Product Experience Data Cloud model: PIM + onboarding + syndication | Launched ProductGen AI for content creation, governance, localization with human-in-loop; architecture described as enterprise-grade | Global enterprises scaling multilingual content | Explicit productized GenAI with governance and approval workflows |
Akeneo | Marketer-friendly PIM; strong UX; SaaS orientation noted | “AI for PX” messaging: data collection, cleansing, enrichment, generation, localization | Marketing-led enrichment / product experience initiatives | Ease-of-use praised; good for marketer workflows |
Salsify | PXM platform model (PIM + syndication + network + workflows) | GenAI accelerator integrated into workflow with human review; TEI shows strong ROI for supplier collaboration/listing acceleration | Brands/retailers optimizing digital shelf + supplier collaboration | Quantified TEI: ROI 375% and rapid payback in composite case |
Syndigo | Strength in distribution/analytics; “hub” approach | Research focus on product content and consumer impact; platform scope includes PIM/MDM via acquisition | Enterprises prioritizing syndication networks | Strong in distribution and optimization analytics per evaluation |
inRiver | End-to-end product content lifecycle with AI-driven automation and governance layers | Explicit “AI maps/structures/identifies gaps” ingestion and AI-driven enrichment workflows | B2B manufacturers with complex assortments | Strength in enrichment, distribution, optimization (marketer priorities) per evaluation |
Pimcore | PIM positioned with open architecture and integrated AI/ML capabilities | “Integrated AI/ML capabilities” positioning, ecosystem-driven GenAI add-ons | Enterprises seeking platform extensibility | Open architecture for integration/scalability |
Open-source and ecosystem building blocks (for “build the GenAI layer”)
A practical enterprise build typically composes open-source components around retrieval, orchestration, and evaluation:
Vector databases (e.g., Weaviate) for embeddings and hybrid retrieval.
Orchestration frameworks (e.g., LangChain) for agentic retrieval and tool-calling patterns.
Pipeline frameworks (e.g., Haystack) for production RAG and agent workflows.
EIC implication: these reduce “time to first prototype,” but do not eliminate the need for enterprise security controls, evaluation harnesses, and operational ownership.
Buy vs Build
Decision criteria
Buy is favored when:
The enterprise lacks a mature PIM/MDM hub (or has one that cannot support modern workflow + API integration + multi-channel syndication). Independent evaluation highlights mature stand-alone PIM offerings and broad enterprise adoption as inclusion criteria.
Speed-to-value and proven governance are board-level priorities, especially with EU AI Act timelines and DPP momentum.
Build (or heavy extend) is favored when:
A strong PIM/MDM already exists and is stable, and the enterprise primarily needs GenAI workflow automation and retrieval grounding rather than replacing the core.
Data residency, industry regulation, or IP constraints strongly limit SaaS usage, pushing toward hybrid/on-prem patterns.
TCO model (illustrative structure)
A disciplined TCO model should partition costs into:
Cost component | Buy PIM + embed GenAI | Build GenAI layer on existing PIM/MDM | Build full PIM + GenAI |
|---|---|---|---|
Core capability | License + vendor roadmap | Existing sunk cost | Large engineering program |
Implementation | SI + data migration + workflow design | Integration + metadata/indexing + UX | Multi-year build, migration, and change |
GenAI ops | Vendor-provided features + your guardrails | Your RAG stack + evaluation + security | Same as “build layer” plus core ops |
Risk | Vendor lock-in; roadmap dependency | Higher engineering and security burden | Highest delivery risk and time-to-value risk |
Independent enterprise AI maturity research indicates that governance, metrics, and data quality drive success and longevity of AI initiatives; the more you build yourself, the more these become your operational responsibility.
Recommended option for most large enterprises
Recommendation: Buy or standardize the PIM/MDM foundation; Build a governed GenAI augmentation layer that is portable across LLM providers and supports multiple product domains and regions. This aligns with:
RAG as the prevailing grounding architecture in research and cloud reference patterns,
enterprise security guidance emphasizing prompt injection, sensitive information disclosure, and excessive agency risks (which require enterprise controls regardless of vendor),
EU AI Act timelines that make documentation, traceability, and governance non-optional.
Financial impact
Cost model (capex/opex framing)
A realistic EIC financial model should distinguish:
One-time investment (capex-like): data model/taxonomy work, connector build, migration, workflow redesign, change management, evaluation harness creation.
Run costs (opex): platform subscriptions, LLM usage (tokens + embedding refresh), vector/search infrastructure, monitoring/observability, red-team testing, and ongoing prompt/workflow tuning. Security risks such as model DoS and sensitive information disclosure have direct opex implications.
Anchoring evidence from TEI-style quantified impacts
Vendor-commissioned TEI evidence (useful as a benchmark, not a guarantee) shows that:
Streamlining supplier collaboration and product data collection can reduce listing time materially (e.g., 28-day reduction in one composite case) and generate significant incremental profit over five years, with a reported ROI of 375% and payback in <6 months for that composite.
Quantified benefits may include efficiency gains, retirement of legacy systems, and avoidance of non-compliance penalties tied to sensitive product data (composition/allergens, etc.).
Sensitivity analysis framework (what to stress-test)
The main sensitivities in GenAI-for-PIM economics are:
Automation rate vs. required human review (hallucination/compliance risk can cap automation).
SKU and language complexity (value increases nonlinearly with localization and channel proliferation).
Revenue sensitivity to product content quality (abandonment/returns linkage). Consumer research indicates strong behavioral impact, supporting upside scenarios when correctness and completeness improve.
Data quality readiness (poor data increases remediation cost and reduces GenAI output reliability).
Risk management
Risk management for GenAI-for-PIM must be treated as an enterprise control system, not a checklist. Two widely adopted governance anchors are:
NIST AI RMF 1.0 (GOVERN, MAP, MEASURE, MANAGE) for lifecycle risk management and trustworthiness characteristics,
ISO/IEC 42001:2023 as a management-system standard for establishing and continuously improving an AI management system.
Additionally, GenAI-specific application security risks are cataloged in OWASP’s Top 10 for LLM applications (prompt injection, sensitive information disclosure, excessive agency, etc.).
Principal enterprise risks and mitigation controls
Data privacy and confidentiality
Risk: leakage of confidential supplier terms, unreleased product plans, or personal data contained in supplier communications.
Controls: strict access control and retrieval filtering; data minimization; redaction/DLP before indexing; audit logging; segregation of environments. EU AI Act emphasizes logging/traceability and human oversight for riskier systems, while data governance policy aims to increase trustworthy data sharing mechanisms.
Intellectual property (IP) and content provenance
Risk: GenAI-generated descriptions inadvertently reproduce copyrighted text from training data or scraped competitor content; unclear provenance for regulatory claims.
Controls: RAG sourcing from enterprise-owned or licensed corpora; citation links to source documents; similarity checks; human approval for externally published copy; dataset documentation and training-data transparency expectations for upstream model providers (relevant under EU GPAI obligations).
Hallucinations and factual errors
Risk: incorrect specifications (dimensions, materials, allergens) create customer harm, returns, or regulatory exposure.
Controls: RAG grounding; constrained generation (templates); validation against structured attributes; confidence scoring; “no-answer” behaviors; mandatory human review for regulated categories. Research surveys describe RAG as addressing hallucination and stale knowledge by incorporating external knowledge bases.
Prompt injection and supply chain vulnerabilities
Risk: malicious content embedded in supplier documents or web pages manipulates the model into exfiltrating data or bypassing policy.
Controls: content sanitization; isolation of untrusted inputs; tool access gating; allowlist-based function calling; security testing aligned to OWASP LLM Top 10 (LLM01 prompt injection, LLM05 supply chain vulnerabilities, LLM06 sensitive information disclosure, LLM08 excessive agency).
Compliance and audit readiness (EU focus)
Risk: failing to meet EU AI Act transparency requirements or future DPP reporting obligations; inability to evidence how product data was derived.
Controls: maintain decision logs (prompt, retrieved context IDs, model version, approver); retain source evidence; align governance to NIST/ISO management systems; implement model and workflow change control. EU AI Act application timeline and DPP implementation activities indicate that compliance expectations will increase over 2025–2027.
Governance operating model (minimum viable)
For an enterprise PIM GenAI program, the minimum viable governance model is:
Accountable owner (enterprise product data + AI governance) and a cross-functional steering group, consistent with AI maturity findings that governance and metrics correlate with sustained production value.
Model risk tiering by product category and jurisdiction (e.g., food/health claims vs. low-risk consumer goods), mapped to EU AI Act risk logic where relevant.
Continuous evaluation (offline test sets + regression testing) for each major workflow (attribute extraction, content generation, translation) as recommended by RAG research emphasizing evaluation and benchmarks.
View more articles
Learn actionable strategies, proven workflows, and tips from experts to help your product thrive.


